Regression Models: Performance Comparison Across Datasets¶
This notebook compares three different approaches to modeling conditional probability distributions using Gaussian Mixture Models. We'll test them on various datasets to see which works best for different types of problems.
The Three Models¶
1. ConditionalGMMRegressor
What it does: Fits a joint Gaussian mixture to all variables [X, y] together, then uses mathematical conditioning to get p(y|X)
Pros: Simple, fast, interpretable
Cons: May not be optimal for conditional prediction since it optimizes the joint distribution
2. MixtureOfExpertsRegressor
What it does: Uses a "gating network" to decide which Gaussian expert should handle each input, where each expert has a linear relationship between X and y
Pros: Can capture complex, non-linear conditional relationships
Cons: More complex, requires more iterations to converge
3. DiscriminativeConditionalGMMRegressor
What it does: Directly optimizes the conditional likelihood p(y|X) using a specialized training algorithm
Pros: Often achieves the best conditional prediction performance
Cons: More computationally intensive, requires careful regularization
Datasets¶
We'll test on 6 diverse datasets to see how each model handles different types of problems:
Classification-style problems (predicting features from other features + labels):
Iris: 150 flowers, predict sepal size from petal size and species
Wine: 178 wines, predict chemical properties from other measurements and wine type
Breast Cancer: 569 samples, predict cell features from other measurements and diagnosis
Digits: 1,797 handwritten digits, predict digit appearance from digit labels
Regression problems (predicting continuous targets):
California Housing: 20,640 houses, predict house price from location and demographics
Diabetes: 442 patients, predict diabetes progression from health measurements
Dataset configurations:
IRIS:
Task: Predict sepal size from petal size and flower species
Details: Classic dataset: 150 iris flowers, 4 measurements each. We predict sepal dimensions (length, width) from petal dimensions and species type (setosa, versicolor, virginica).
Setup: 2 targets, 2 conditioning vars, 5 components
WINE:
Task: Predict wine chemistry from other measurements and wine type
Details: Wine quality dataset: 178 wines from 3 different cultivars, 13 chemical measurements each. We predict the first 3 chemical properties from the other 10 measurements plus wine class.
Setup: 3 targets, 10 conditioning vars, 5 components
BREAST_CANCER:
Task: Predict cell features from other measurements and diagnosis
Details: Medical dataset: 569 breast cancer samples, 30 features from cell nuclei images. We predict the first 3 features from the other 27 measurements plus diagnosis (malignant/benign).
Setup: 3 targets, 27 conditioning vars, 5 components
DIGITS:
Task: Predict digit appearance from digit labels
Details: Handwritten digits: 1,797 8x8 pixel images of digits 0-9. We use PCA to reduce 64 pixels to 8 components, then predict these from the digit labels. This tests how well models can learn visual patterns from categorical information.
Setup: 8 targets, 0 conditioning vars, 7 components
CALIFORNIA_HOUSING:
Task: Predict house price from location and demographics
Details: Real estate dataset: 20,640 California housing districts, 8 features including location, demographics, and housing characteristics. We predict median house value from the other 7 features.
Setup: 1 targets, 7 conditioning vars, 5 components
DIABETES:
Task: Predict diabetes progression from health measurements
Details: Medical dataset: 442 diabetes patients, 10 baseline measurements (age, sex, BMI, blood pressure, etc.). We predict disease progression (continuous target) from the other 9 health measurements.
Setup: 1 targets, 9 conditioning vars, 5 components
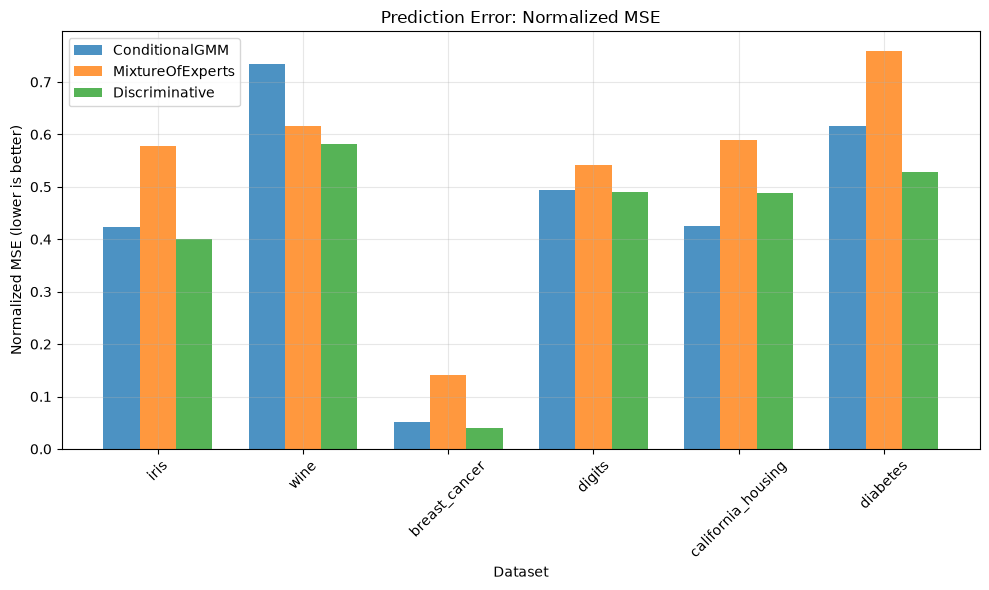
RESULTS SUMMARY
============================================================
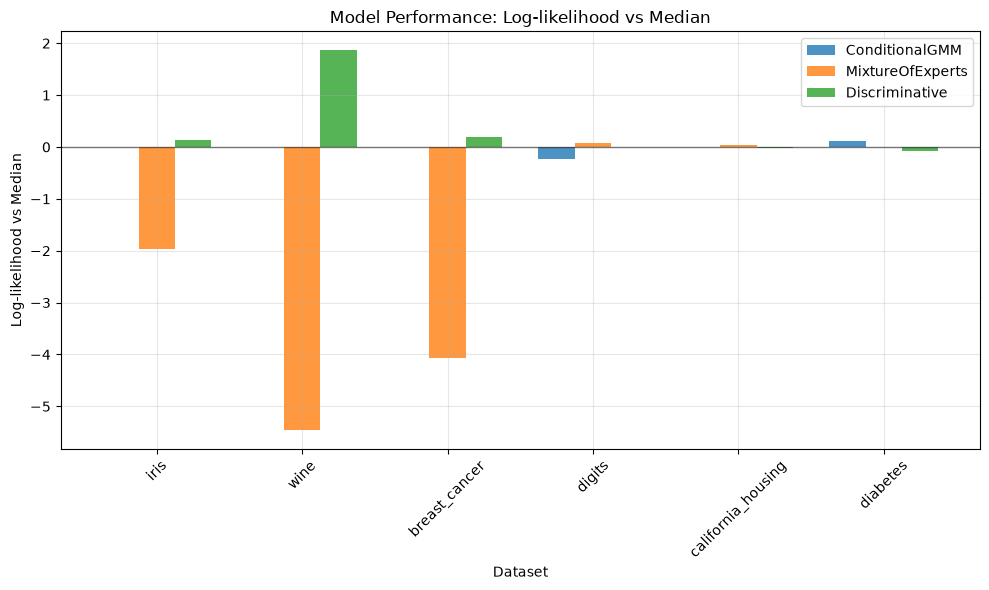
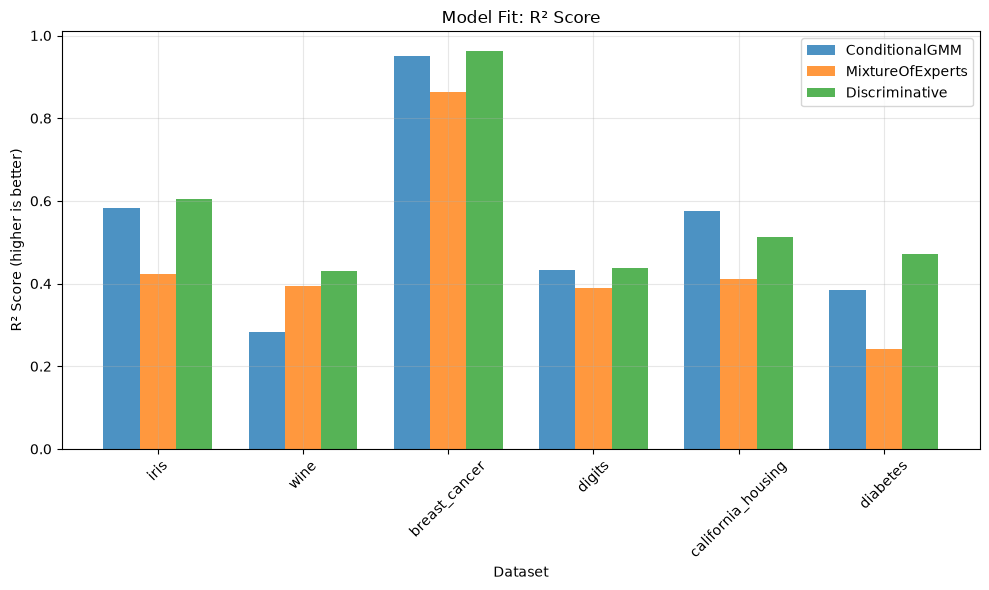
Dataset Model Log-Likelihood R² Iterations
iris ConditionalGMM -1.915 0.582 11
iris MixtureOfExperts -3.881 0.424 38
iris DiscriminativeConditionalGMM -1.786 0.604 6
wine ConditionalGMM -5.387 0.282 2
wine MixtureOfExperts -10.842 0.393 11
wine DiscriminativeConditionalGMM -3.524 0.431 6
breast_cancer ConditionalGMM 1.021 0.951 21
breast_cancer MixtureOfExperts -3.047 0.865 25
breast_cancer DiscriminativeConditionalGMM 1.212 0.962 17
digits ConditionalGMM -11.637 0.434 30
digits MixtureOfExperts -11.321 0.390 45
digits DiscriminativeConditionalGMM -11.396 0.439 23
california_housing ConditionalGMM -1.110 0.575 13
california_housing MixtureOfExperts -1.081 0.412 52
california_housing DiscriminativeConditionalGMM -1.131 0.512 132
diabetes ConditionalGMM -5.508 0.385 56
diabetes MixtureOfExperts -5.626 0.241 18
diabetes DiscriminativeConditionalGMM -5.704 0.472 200
MODEL PERFORMANCE RANKINGS:
========================================
iris → DiscriminativeConditionalGMM
wine → DiscriminativeConditionalGMM
breast_cancer → DiscriminativeConditionalGMM
digits → MixtureOfExperts
california_housing → MixtureOfExperts
diabetes → ConditionalGMM
Total wins:
ConditionalGMM: 1/6
MixtureOfExperts: 2/6
DiscriminativeConditionalGMM: 3/6